Let’s make a package!¶
This recitation was written by Patrick Almhjell.
So, where do we start?
Let’s revisit the code to parse my data and make a plot from before and think about how we could start writing a package based on it.
I know what you may be thinking: “Patrick, you’re dumb, that’s only three functions. It’s certainly not enough for a package.”
And, perhaps you’re right. But a package is designed to be managed, improved, expanded. You will almost never make a package and be done with it in a single commit and push. So, setting the foundation for a package with a few key functions and an idea of how it will expand is just as important as setting up a meaty package.
So, let’s do it!
Setting up the repo on GitHub¶
First thing’s first: we need to set up a repository on GitHub so it’s under version control and (eventually) distributable. It’s very easy.
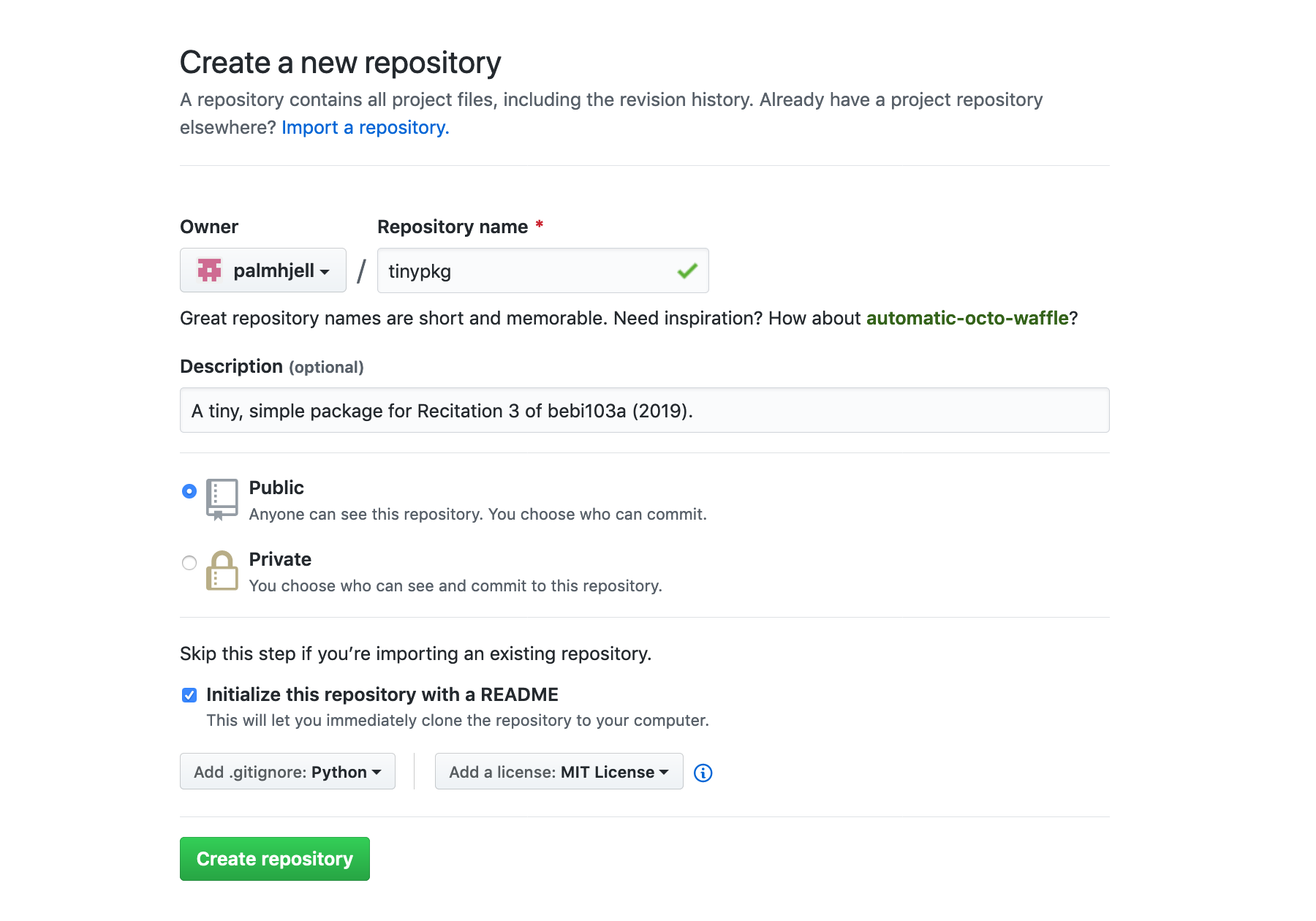
The automatic addition of a .gitignore file is really nice. Here’s some of the contents of the default Python one:
...
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
...
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
...
# Jupyter Notebook
.ipynb_checkpoints
...
You certainly don’t need all of this, but a lot of it is good, especially when working with Jupyter (ignoring .ipynb_checkpoints) and after you build the package (build/, wheels/, egg-info/, etc.).
After doing this, you’ll have a repo on GitHub that you can clone onto your machine and start working with.
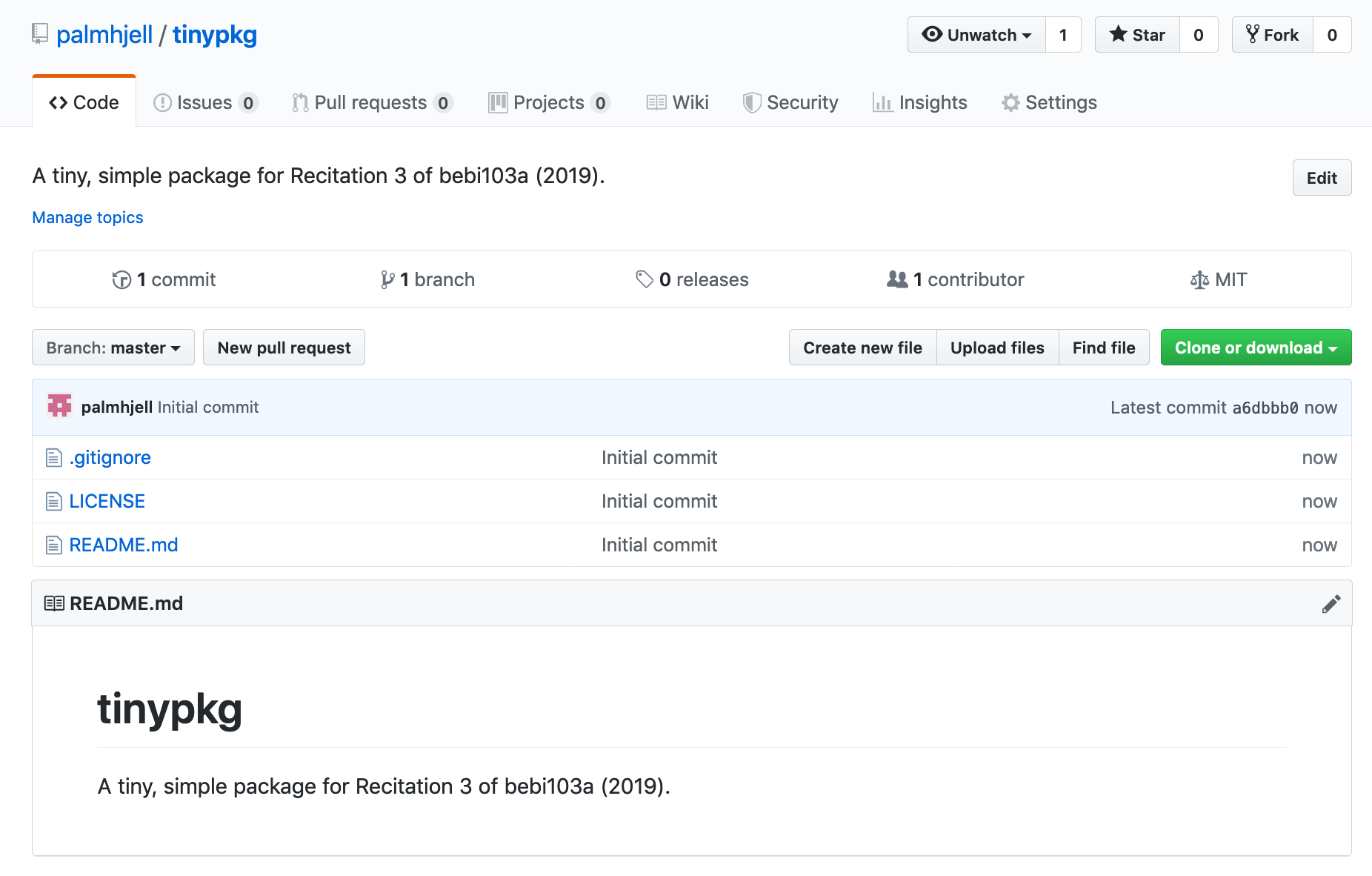
Adding our code¶
As we said in the last section, your package will always follow this format:
/package_name
/package_name
__init__.py
module_1.py
module_2.py
...
...
README.md
So, really all we’re missing is the coding guts of our package… which we already have! We just have to put it into modules and then place them in another directory called tinypkg within our repo.
Now, let’s think about how we want to do this, keeping in mind what we discussed before.
We have three functions. Two of them perform some sort of general utility, and one of them makes a visualization. To me, this seems like it would be well-organized as follows:
/tinypkg
/tinypkg
__init__.py
general_utils.py <------ contains check_df_col() and check_replicates()
viz.py <------ contains plot_timecourse()
...
...
If you read my code, you might disagree. Since check_replicates() at its core is performing data analysis and processing, it might not be a general utility. So perhaps this is better:
/tinypkg
/tinypkg
__init__.py
general_utils.py <------ contains check_df_col()
analysis.py <------ contains check_replicates()
viz.py <------ contains plot_timecourse()
...
...
It’s really up to you. At this point it’s a bit silly to have three functions in three separate files. But I think we can all agree that these don’t belong in the same module.
And, furthermore, this isn’t about now. This is about the future, and helping out Future You! (And your labmates.) When you have more utilities, analysis functions, or plotting functions (which you certainly will, in practice), you know exactly where to put them and how they will interact.
We’ll set this up in the original two-module way. Make these changes in the repo you just cloned and git add, git commit, and git push these changes. You’ll find this:
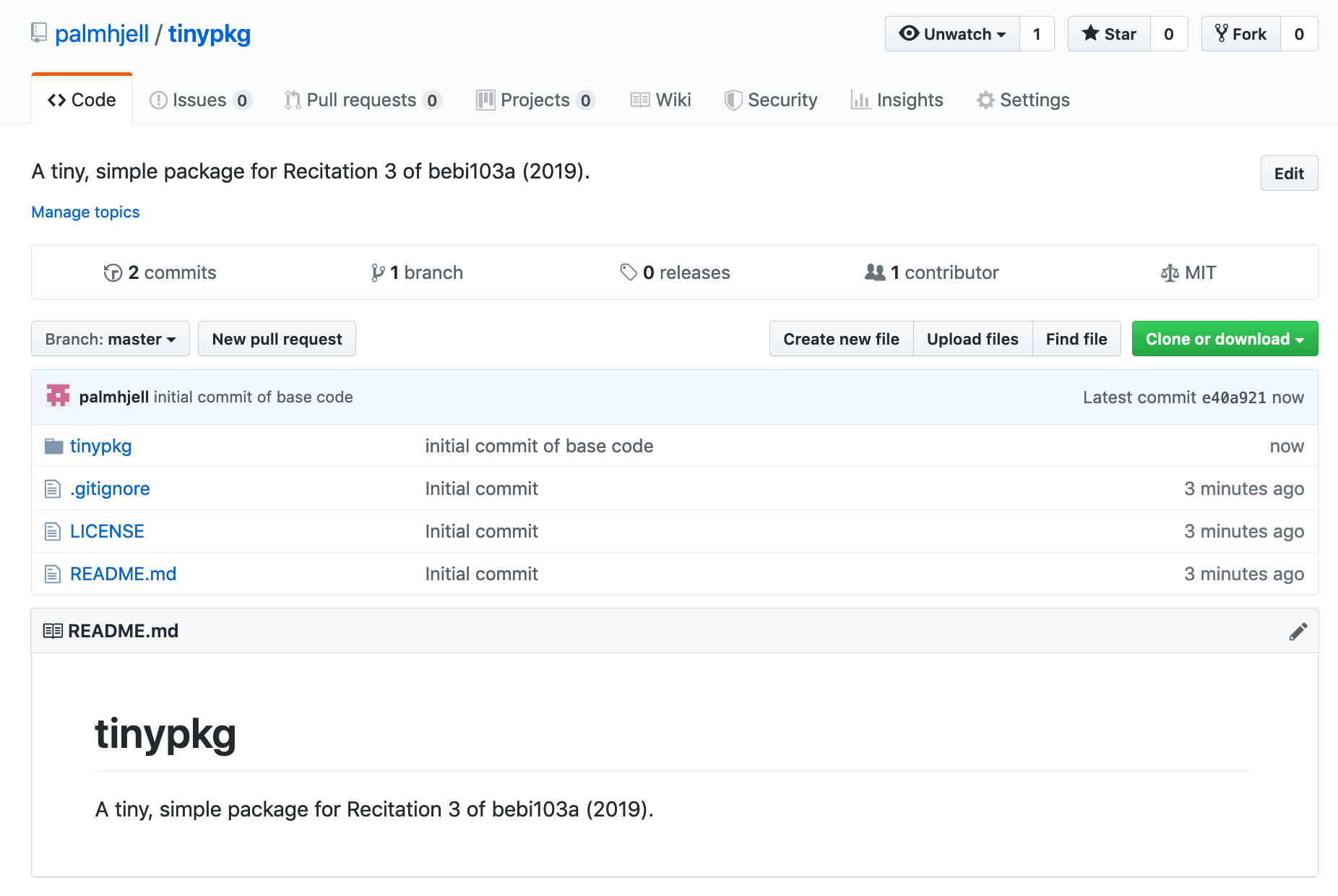
Here’s a look at the modules themselves.
general_utils.py
import numpy as np
import pandas as pd
def check_df_col(df, column, name=None):
# ...
def check_replicates(df, variable, value, grouping):
# ...
viz.py
import numpy as np
import pandas as pd
import holoviews as hv
hv.extension('bokeh')
import tinypkg.general_utils as utils
def plot_timecourse(df, variable, value, condition=None, split=None, sort=None, cmap=None, show_all=False,
show_points='default', legend=False, height=350, width=500, additional_opts={}):
# ...
# Check columns
utils.check_df_col(df, variable, name='variable')
utils.check_df_col(df, value, name='value')
utils.check_df_col(df, condition, name='condition')
utils.check_df_col(df, split, name='split')
utils.check_df_col(df, sort, name='sort')
# ...
# Check for replicates; aggregate df
groups = [grouping for grouping in (condition, split) if grouping is not None]
if groups == []:
groups = None
replicates, df = utils.check_replicates(df, variable, value, groups)
Notice here the import of general_utils.py as utils, which means we call our check_...() functions with utils.check...(). This is nice, because we are very explicit about where we are getting our functions.
And last but not least, we need to add our __init__.py file:
from .general_utils import *
from .viz import *
# ...
You can look through this package on GitHub: https://github.com/palmhjell/tinypkg. It has additional contents not shown above, which you’ll learn about in the next sections.
Computing environment¶
[1]:
%load_ext watermark
%watermark -v -p jupyterlab
CPython 3.7.4
IPython 7.8.0
jupyterlab 1.1.4