Recitation 02: Git/Github Tips and Traps¶
For the purposes of this material, it is assumed that the you have attended & read through Lecture 1b. We’ll start by reviewing some of these concepts and then covering some simple tricks to prevent a whole host of headaches in using GitHub within your groups. The bulk of this lesson, however, will extend on these materials. Specifically, we cover merging, including using jupytext to deal with the oddities of performing these operations on notebooks. If you are looking for a more in-depth tutorial on various Git concepts, reference this tutorial from software carpentry. The goal for today is to get you more comfortable with git than the protagonist of this cartoon.
Simple practices can save from huge pains¶
Git is extremely useful and powerful, but it can cause serious annoyances if not used carefully. Follow Justin’s suggestion from hw1: ‘it is wise to commit and push often.’ And from Lecture 1b, pull frequently and ‘always git pull when you start working.’ These practices will go a long way to prevent clashes where two group members have edited the same file at the same time without knowing. Even if you feel that a particular piece of work is not yet finished, commit and push it any time you step away from it. It is much better for a teammate to look at work you might feel insecure about due to its incompleteness than to have a horrible merge issue later on.
1) Use the sandbox exceedingly liberally¶
The simplest and easiest way to avoid clashing with group members work is to use the sandbox provided in your GitHub repository extensively. When doing this, each member can work on a differently named file. For example, I might work on hw3.2_mm.ipynb, where the mm signifies my initials, while my teammate Suzy works on hw3.2_sb.ipynb. Each team member can have their own version of various pieces of the homework for scratch work. The key reason to do this is that you might not know
when a team member is working on the same file. If two people are working on the same file at the same time, a merge conflict is certain in the near future. One will push to the repository first, leaving changes that the other does not have in the file they are working with. This means that if the second forces a push, their changes will be kept at the expense of the other’s. Without additional tools, merging notebooks with disparate changes is very non-trivial. Instead, to avoid all this,
both members can work on their own files in the sandbox, discuss various parts, and combine and edit a final submission when the time comes.
Note that if you open two Jupyter notebooks next to each other in JupyterLab it is quite easy to create a combined version of a document. This is much better than overwriting each other repeatedly.
2) Use checkout to avoid destroying others work¶
When you use separate files for each team member in the sandbox, you will often want to look at and build in the work of your teammates. This means that you will often pull material from the repo and open the notebooks of others. If you run this notebook and poke around in it, you may make a “change” in the document that you do not intend to. If you commit and push this change, you might cause a merge conflict with changes the owner of this file has made since you last pulled. If you insist on
pushing, you might destroy another’s work. If you check git status and see a change in such a file that you don’t want to push, use git checkout FILE_NAME_HERE to discard your non-change-changes and prevent later merge conflicts. Your teammates will thank you!
Configuration & basics¶
If you haven’t done so already, make sure to configure your Git parameters. Namely, you must set your contact information and name. Ignore if you already did this when setting up for the class.
git config --global user.name "YOUR NAME"
git config --global user.email "YOUR EMAIL ADDRESS"
Naturally, you fill in the name and email with your details.
For the purposes of this exercise, we will be playing around with a repository set up specifically for practice. Justin recommends to store cloned and forked GitHub repos in a folder called git in your home directory. I will assume this convention for this tutorial. For today, please fork the repository located at https://github.com/muirjm/gitbrachmerge. This can be done in GitHub using the browser, using the ‘Fork’ button on the upper right side of the page when you navigate to the
repository. Select that you want to fork it to your personal GitHub organization, not the BE/Bi 103 one, to avoid clutter there. Once you do this fork, clone the repository by copying the URL and performing
cd ~/git
git clone URL YOU COPIED
You should additionally already be familiar with the following commands from Lecture 1b:
git status
git add
git commit
git push
For additional help with these commands and their uses (as well as a bunch of other useful commands) reference this cheat sheet from GitHub. This very handy reference shows all the commands you are likely to need and then some.
Syncing your forked repository to the upstream repository¶
For this course, you will do all your work with your teammates in a single repo. You will not need to deal with forking repos, but for today, this is the easiest way to demonstrate merge clashes and how to deal with them. You want to be able to sync your repository with my gitbranchmerge repository so you can retrieve any updates in it. The original repository is typically called the upstream repository, since presumably you are changing it, so you are downstream. You want the upstream
repository to be a remote repository, which is just what we call a repository we track and fetch and merge from. To see which repositories are remote, do
git remote -v
The -v just means “verbose,” so it will also tell you the URLs. Entering that now will show a single repository, origin, which you can fetch from and push to. In your case, origin is your fork of the gitbranchmerge repository.
We now want to add the upstream repository. To do this, copy the URL of my gitbranchmerge repository and then do:
git remote add upstream the_url_you_just_copied
Now try doing git remote -v, and you will see that you are now also tracking the upstream repository.
Now, when you want to pull from the upstream repository, you do
git pull upstream master
This will pull in all the changes from the upstream repository. If you want to pull in changes to your own forked repository, it’s still just
git pull
which is shorthand for
git pull origin master
Merging¶
If possible, avoid merging¶
The best way to merge is to avoid merging in the first place. This is doubly true when working with Jupyter notebooks. The simple practices above are meant to help avoid the need to merge. Here are some more excellent tips on avoiding the need to merge from a tutorial from software carpentry. These include some more advanced features of git than we’ve covered today, like branches, but they are nevertheless good advice, especially the project management strategies:
Git’s ability to resolve conflicts is very useful, but conflict resolution costs time and effort, and can introduce errors if conflicts are not resolved correctly. If you find yourself resolving a lot of conflicts in a project, consider these technical approaches to reducing them:
Pull from upstream more frequently, especially before starting new work
Use topic branches to segregate work, merging to master when complete
Make smaller more atomic commits
Where logically appropriate, break large files into smaller ones so that it is less likely that two authors will alter the same file simultaneously
Conflicts can also be minimized with project management strategies:
Clarify who is responsible for what areas with your collaborators
Discuss what order tasks should be carried out in with your collaborators so that tasks expected to change the same lines won’t be worked on simultaneously
If the conflicts are stylistic churn (e.g. tabs vs. spaces), establish a project convention that is governing and use code style tools (e.g. htmltidy, perltidy, rubocop, etc.) to enforce, if necessary
Daisie Huang and Ivan Gonzalez (eds): “Software Carpentry: Version Control with Git.” Version 2016.06, June 2016, https://github.com/swcarpentry/git-novice, 10.5281/zenodo.57467.
Merging with simple text files¶
Excersise 1¶
We will first play around with the simplest case of merges by dealing with text files. In the repository you forked, there is a text file called text_merge/edit_me.txt. We will play around with editing this file concurrently with two people and deal with the resulting merge issues. Open this file in your favorite text editor and add a few lines. This could be accomplished, for example, with
cd ~/git/gitbranchmerge/text_merge
vim edit_me.txt
When you are done editing the file save the file and exit. (In vim, tap i for insert, then navigate with arrow keys and make your edits. When done, tap ESC, then type :wq, for write & quit, then Enter. If you make a mistake and want to bail without saving, use ESC, then :q, Enter).
In the mean time, I have also edited this document, committed, and pushed it to the upstream master repo. If you pull from the upstream master, you will get a prompt to merge. Try this now:
git pull uptream master
If we didn’t edit the same lines, Git should be able to automerge the edit_me.txt file. But if we did make edits to the same lines, Git doesn’t know which version to keep, yours or mine! To handle this merge, you need to manually edit the document and deal with the discrepancies. Otherwise, you’ll end up publishing material with merge issues like this:
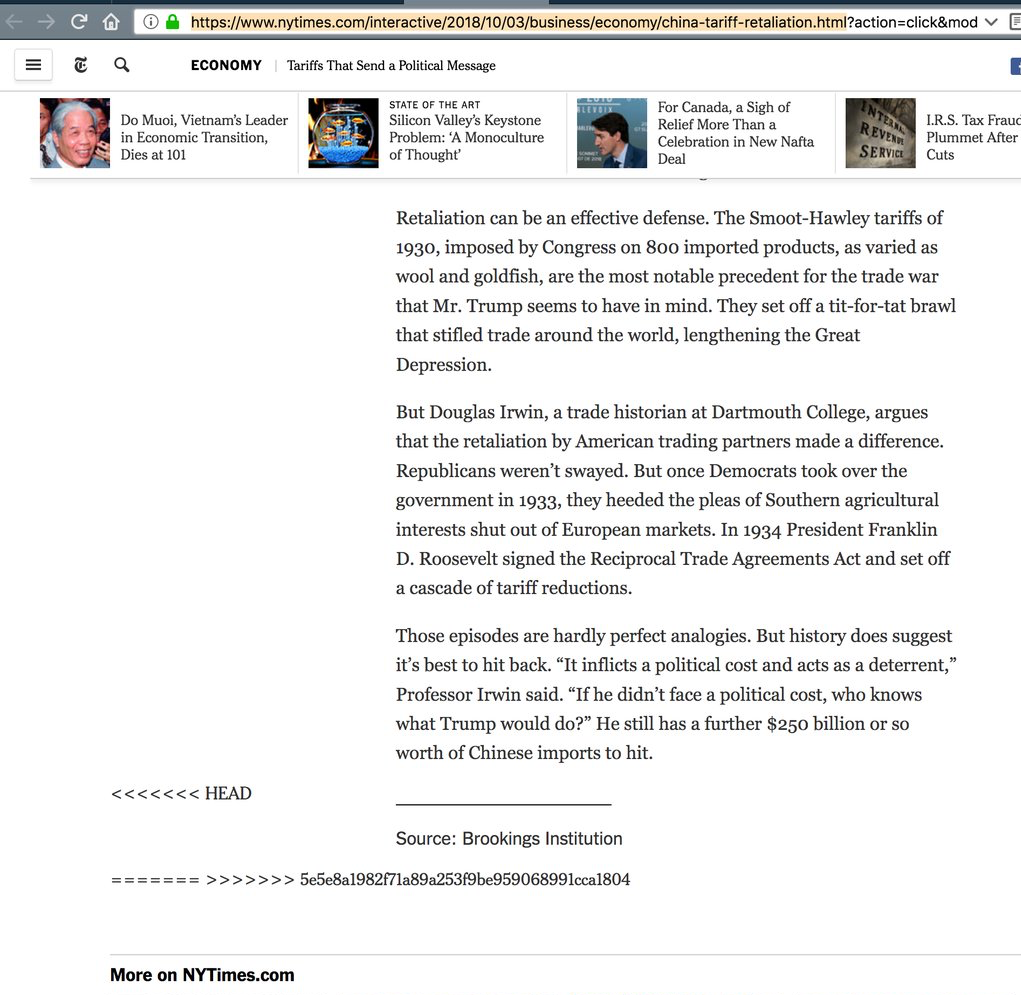
<<<<<<<HEAD indicates the change (in the above case an insertion) from the master, and the material below the ======= shows changes from your local end.
For a simple file like this, doing this manual merge is not impossible. You can use your favorite text editor to manually edit the document and decide which lines to keep or remove. When you have done this, you can add, commit, and push the changes to your forked version of the repo.
git add edit_me.txt
git commit -m 'merge edit_me.txt with upstream edits'
git push origin master
You have now dealt with the discrepancies like a champ!
Merging Jupyter Notebooks¶
Exercise 2¶
We will now run through the same experiment as before, but this time each will edit the simple Jupyter notebook stored in notebook_merging/simple_notebook.ipynb. The resulting merge will not be so simple to deal with since the internal formatting of Jupyter notebooks is not very human readable. Open the document, change a plot, maybe add a cell or two the the file, and save. Try to reconcile this with upstream master after I push a change myself.
Note also that if you have a merge conflict with notebooks, the inserts that git adds to flag the conflict will break the formatting of the notebook, so the notebook will become unreadable to Jupyterlab. If this happens, you can use git merge --abort to at least return your notebook to a readable format. Since there is no easy way to merge notebooks, your least bad option may actually be the recipe suggested in the cartoon we started with.
Jupytext¶
Jupytext is a relatively new package that promises to combine the best of both worlds of notebooks (interactivity, inline plots, and beyond) and plain python scripts (easy version control & merging). Its integration with Jupyterlab is a work in progess, so caveat emptor. On my system, the newer versions of jupytext prevent me from saving notebooks at all (though I haven’t ruled out that the problem is on my end and not intrinsic to the package, and YMMV). We will instead explore the
command line options available.
The valuable addition that such a package provides is a conversion of notebooks into scripts of various types (.py, .md) that can then be easily version controlled with meaningful and human-readable merges. To begin, you will need to install jupytext. This is a simple pip install. Note the explicit version number since we do not want the newest version available.
pip install jupytext==0.8.6
This is all you need to have to start using the tools. You can explore the ways of automatically going back and forth between a text file and notebook by editing the metadata preferences for your notebooks, but I have found this to be more trouble than it’s worth. To make a python script file that represents your Jupyter notebook, you can simply use
jupytext --to python notebook.ipynb
The result of this script is a .py file with your code and markdown cells formatted together. Better yet, since .py files are really just text, merge tools of git will work for them! You can store your notebooks on GitHub as this .py file, and then easily convert it to a notebook after pulling it. This conversion is achieved with
jupytext --to notebook notebook.py
(The conversion from .py to .ipynb may give you a deprecation warning; it works fine, but has security vulnurabilities, so maybe don’t run this on random scripts from the internet.)
Jupytext has been heavily tested, ensuring that the result you get from a conversion and back gives the same notebook as you started with.
Exercise 3¶
Try out the same experiment we did with the text file and the Jupyter notebook on the jupytext document. Convert the file to a notebook with the above command, add a cell or two, save, convert back to a .py file, and try to merge with changes I made to the same file.
A new workflow in your repos¶
Based on the power of merging with a text based file, a better workflow for your repository would be to store your sandbox work in .py files generated with jupytext instead of pushing as notebooks. With this, you need not bother version controlling your .ipynb files at all. In addition to aiding with merges, this also helps limit the size of your repository: the text file is much smaller than a notebook, especially one that has glyph-heavy plots in it. The suggested work flow is as follows:
Edit your work in jupyter lab
Save your notebook and keep it locally
Convert your notebook to a .py file
Add, commit, and push this .py file to GitHub
Pull, convert to a notebook, and repeat
A final note on commit messages¶
Git really comes into its own for managing larger projects than your homework assignments in this course. One key ingredient of good version control in this context is writing informative commit messages. Justin emphasized in Lecture 2 that the emphasis of comments in code should be why, not how. The important information is why was a design choice made, what was it’s context, and not the implementation details (the how), which should be fairly self-evident from good self-documenting code. Future You is the most important reader.
All of these same thoughts apply to commit messages. Their goal is to give context and explain why, not how, changes were made. I highly recommend this post on how to write good commit messages. This may sound like a silly thing to harp on, so read that blog post for more insight on why your git log --oneline should never look like this.
Copyright note: In addition to the copyright shown below, this recitation uses material written by Julian Wagner.