Display of MCMC samples¶
[1]:
import numpy as np
import pandas as pd
import cmdstanpy
import arviz as az
import bokeh_catplot
import bebi103
import holoviews as hv
hv.extension('bokeh')
bebi103.hv.set_defaults()
import bokeh.io
bokeh.io.output_notebook()


In a previous lesson, we learned how to use Stan to sample out of posterior distributions specified by a generative model. In this lecture, we will learn about some techniques to visualize the results. As our first working example, we will consider again the conserved tubulin spindle size model, discussed at length previously, using the data set from Good, et al., Science, 342, 856-860, 2013.
We is a quick look at the data set.
[2]:
df = pd.read_csv('../data/good_invitro_droplet_data.csv', comment='#')
hv.Scatter(
data=df,
kdims='Droplet Diameter (um)',
vdims='Spindle Length (um)',
)
[2]:
Visualization with ArviZ¶
ArviZ has lots of handy visualization of MCMC results, and it is a very promising package to use to quickly get plots. It currently still has some drawbacks. First, some plots are not rendered properly with Bokeh. This problem will likely be fixed very soon with future releases. Second, some of the aesthetic choices in the plots would not be my first choice. There are other specific drawbacks to the ArviZ visualizations that I will point out as we go along.
For each of the visualizations below, I show how to construct the visualization using ArviZ, but also using the bebi103 package.
The model and samples¶
We will briefly repeat the sampling of the model as we did in a previous lesson. As a reminder, the model is
\begin{align} &\phi \sim \text{LogNorm}(\ln 20, 0.75),\\[1em] &\gamma \sim \text{Beta}(1.1, 1.1), \\[1em] &\sigma = \text{HalfNorm}(10,\\[1em] &\mu_i = \frac{\gamma d_i}{\left(1+(\gamma d_i/\phi)^3\right)^{\frac{1}{3}}} \;\forall i, \\[1em] &l_i \mid d_i, \gamma, \phi, \sigma \sim \text{Norm}(\mu_i, \sigma) \;\forall i. \end{align}
We used the following Stan code to implement this model.
functions {
real ell_theor(real d, real phi, real gamma_) {
real denom_ratio = (gamma_ * d / phi)^3;
return gamma_ * d / (1 + denom_ratio)^(1.0 / 3.0);
}
}
data {
int N;
real d[N];
real ell[N];
}
parameters {
real phi;
real gamma_;
real<lower=0> sigma;
}
model {
phi ~ lognormal(log(20.0), 0.75);
gamma_ ~ beta(1.1, 1.1);
sigma ~ normal(0.0, 10.0);
for (i in 1:N) {
ell[i] ~ normal(ell_theor(d[i], phi, gamma_), sigma);
}
}
Let’s obtain some samples so we can start to look at visualizations.
[3]:
sm = cmdstanpy.CmdStanModel(stan_file='spindle.stan')
data = dict(
N=len(df),
d=df["Droplet Diameter (um)"].values,
ell=df["Spindle Length (um)"].values,
)
samples = sm.sample(
data=data,
chains=4,
sampling_iters=1000,
)
samples = az.from_cmdstanpy(posterior=samples)
INFO:cmdstanpy:stan to c++ (/Users/bois/Dropbox/git/bebi103_course/2020/b/content/lecture_notes/lecture_04/spindle.hpp)
INFO:cmdstanpy:compiling c++
INFO:cmdstanpy:compiled model file: /Users/bois/Dropbox/git/bebi103_course/2020/b/content/lecture_notes/lecture_04/spindle
INFO:cmdstanpy:start chain 1
INFO:cmdstanpy:start chain 2
INFO:cmdstanpy:finish chain 2
INFO:cmdstanpy:start chain 3
INFO:cmdstanpy:finish chain 1
INFO:cmdstanpy:start chain 4
INFO:cmdstanpy:finish chain 3
INFO:cmdstanpy:finish chain 4
Examining traces¶
The first type of visualization we will explore is useful for diagnosing potential problems with the sampler.
Trace plots¶
Trace plots are a common way of visualizing the trajectory a sampler takes through parameter space. We plot the value of the parameter versus step number. You can make these plots using bebi103.viz.trace_plot(). By default, the traces are colored according to chain number. In our sampling we just did, we used Stan’s default of four chains.
Trace plots with ArviZ¶
To make plots with ArviZ, the basic syntax is az.plot_***(samples, backend='bokeh'), where *** is the kind of plot you want. The backend='bokeh' kwarg indicates that you want the plot rendered with Bokeh. Let’s make a trace plot.
[4]:
az.plot_trace(samples, backend='bokeh');
ArviZ generates two plots for each variable. The plots to the right show the trace of the sampler. In this plot, the x-axis is the iteration number of the steps of the walker and the y-axis is the values of the parameter for that step.
ArviZ also plots a picture of the marginalized posterior distribution for each trace to the left. The issue I have these plots because they use kernel density estimation for the posterior plot. KDE involves selecting a bandwidth, which leaves an adjustable parameter. I prefer simply to plot the ECDFs of the samples to visualize the marginal distributions, as I show below.
Trace plots with bebi103¶
To make trace plots with the bebi103 module, you can do the following.
[5]:
bokeh.io.show(
bebi103.viz.trace_plot(samples)
)
Interpetation of trace plots¶
These trace plots look pretty good; the sampler is bounding around a central value. Trace plots are very commonly used, which is why I present them here, but are not particularly useful. This is not just my opinion. Here is what Dan Simpson has to say about trace plots.
Parallel coordinate plots¶
As Dan Simpson pointed out in his talk I linked to above, plots that visualize diagnostics effectively are better. We will talk more about diagnostics of MCMC in later lessons, but for now, I will display one of the diagnostic plots Dan showed in his talk. Here, we put the parameter names on the x-axis, and we plot the values of the parameters on the y-axis. Each line in the plot represents a single sample of the set of parameters.
Parallel coordinate plots with ArviZ¶
[6]:
az.plot_parallel(samples, backend='bokeh');
To make sure we compare things of the same magnitude so we can better see the details of how the parameters vary with respect to each other, we scale the samples by the minimum and maximum values.
[7]:
az.plot_parallel(samples, backend='bokeh', norm_method='minmax');
Parallel coordinate plots with bebi103¶
[8]:
bokeh.io.show(
bebi103.viz.parcoord_plot(
samples,
transformation="minmax",
pars=["phi", "gamma_", "sigma"],
)
)
Intepretation of parallel coordinate plots¶
Normally, samples with problems are plotted in another color to help diagnose the problems. In this particular set of samples, there were no problems, so everything looks fine.
Interestingly, the “neck” between phi and gamma_ is indicative of anticorrelation. When φ is high, γ is low, and vice-versa.
Plots of marginalized distributions¶
While we cannot in general plot a multidimensional distribution, we can plot marginalized distributions, either of one parameter or of two.
Plotting marginalized distributions of one parameter¶
There are three main options for plotting marginalized distributions of a single parameter.
A kernel density estimate of the marginalized posterior.
A histogram of the marginalized posterior.
An ECDF of the samples out of the posterior for a particular parameter. This approximates the CDF of the marginalized distribution.
I prefer (3), though (2) is a good option as well. For continuous parameter, ArviZ offers only a KDE plot.
Plotting marginalized distributions with ArviZ¶
We already saw that ArviZ can give these plots along with trace plots. We can also directly plot them using the az.plot_density(). When using this function, the distributions are truncated at the bound of the highest probability density region, or HPD. If we’re considering a 95% credible interval, the HPD interval is the shortest interval that contains 95% of the probability of the posterior. By default, az.plot_density() truncates the plot of the KDE of the PDF for a 94% HPD.
[9]:
az.plot_density(samples, backend='bokeh', figsize=(11, 4));
Plotting marginalized distributions with bokeh_catplot¶
To get samples out of the marginalized posterior for a single parameter, we simply ignore the values of the parameters that are not the one of interest. We can then use bokeh_catplot to make plots of histograms or ECDFs.
To do so, we need to convert the posterior samples to a tidy data frame.
[10]:
# Convert to data frame
df_mcmc = bebi103.stan.posterior_to_dataframe(samples)
# Take a look
df_mcmc.head()
[10]:
| phi | gamma_ | sigma | chain__ | draw__ | divergent__ | |
|---|---|---|---|---|---|---|
| 0 | 38.0806 | 0.864203 | 3.89075 | 0 | 0 | False |
| 1 | 37.9615 | 0.892443 | 3.81473 | 0 | 1 | False |
| 2 | 38.0900 | 0.875571 | 3.79352 | 0 | 2 | False |
| 3 | 37.9592 | 0.854862 | 3.80171 | 0 | 3 | False |
| 4 | 38.3422 | 0.851406 | 3.65188 | 0 | 4 | False |
Now, we can use bokeh_catplot to make histograms.
[11]:
hists = [
bokeh_catplot.histogram(
df_mcmc, val=val, density=True, x_axis_label=val, frame_height=150
)
for val in ["phi", "gamma_", "sigma"]
]
bokeh.io.show(bokeh.layouts.gridplot(hists, ncols=1))
A better option, in my opinion, is to make ECDFs of the samples.
[12]:
ecdfs = [
bokeh_catplot.ecdf(
df_mcmc, val=val, x_axis_label=val, frame_height=150
)
for val in ["phi", "gamma_", "sigma"]
]
bokeh.io.show(bokeh.layouts.gridplot(ecdfs, ncols=1))
Marginal posteriors of two parameters¶
We can also plot the two-dimensional distribution (of most interest here are the parameters \(\phi\) and \(\gamma\)). The simplest way to plot these is simple to plot each point, possibily with some transparency.
[13]:
hv.Points(
df_mcmc,
kdims=[('phi', 'ϕ [µm]'), ('gamma_', 'γ')],
).opts(
alpha = 0.1,
size=2,
)
[13]:
Pair plots with ArviZ¶
We might like to do this for all pairs of plots. ArviZ enables this to be done conveniently.
[14]:
az.plot_pair(samples, backend='bokeh', figsize=(8, 8));
ArviZ also offers pair two-dimensional binning in the form of a hex plot. (This does not work properly with a Bokeh backend.)
[15]:
az.plot_pair(samples, kind='hexbin', figsize=(8, 8));
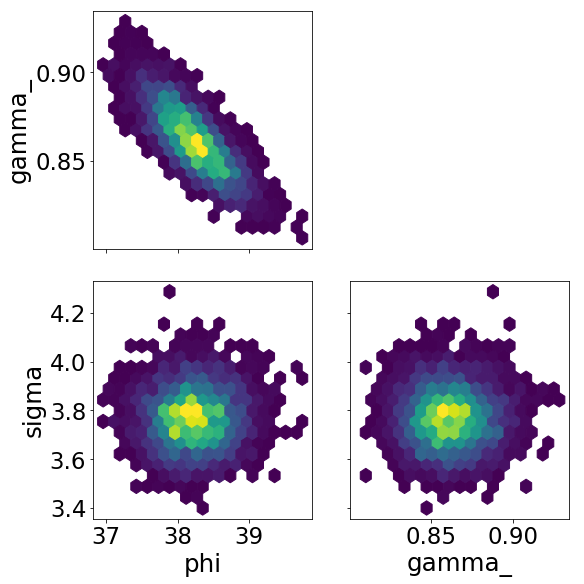
Corner plots¶
It would be convenient to plot all visualizable marginal distributions (that is one- and two-dimensional distribution). We can conveniently do that with a corner plot, implemented in the bebi103 package.
[16]:
bokeh.io.show(
bebi103.viz.corner(
samples,
pars=["phi", "gamma_", "sigma"],
labels=["ϕ [µm]", "γ", "σ [µm]"],
xtick_label_orientation=np.pi / 4,
)
)
This is a nice way to summarize the posterior and is useful for visualizing how various parameters covary. We can also do a corner plot with the one-parameter marginalized posteriors represented as CDFs.
[17]:
bokeh.io.show(
bebi103.viz.corner(
samples,
pars=["phi", "gamma_", "sigma"],
labels=["ϕ [µm]", "γ", "σ [µm]"],
plot_ecdf=True,
xtick_label_orientation=np.pi / 4,
)
)
In my view, this last plot is my preferred method of displaying results. All possible display-able marginal posteriors are plotted and laid out in a logical way.
[18]:
bebi103.stan.clean_cmdstan()
Computing environment¶
[19]:
%load_ext watermark
%watermark -v -p numpy,pandas,cmdstanpy,arviz,bokeh,holoviews,bokeh_catplot,bebi103,jupyterlab
CPython 3.7.6
IPython 7.11.1
numpy 1.18.1
pandas 0.24.2
cmdstanpy 0.8.0
arviz 0.6.1
bokeh 1.4.0
holoviews 1.12.7
bokeh_catplot 0.1.7
bebi103 0.0.50
jupyterlab 1.2.5