Solution¶
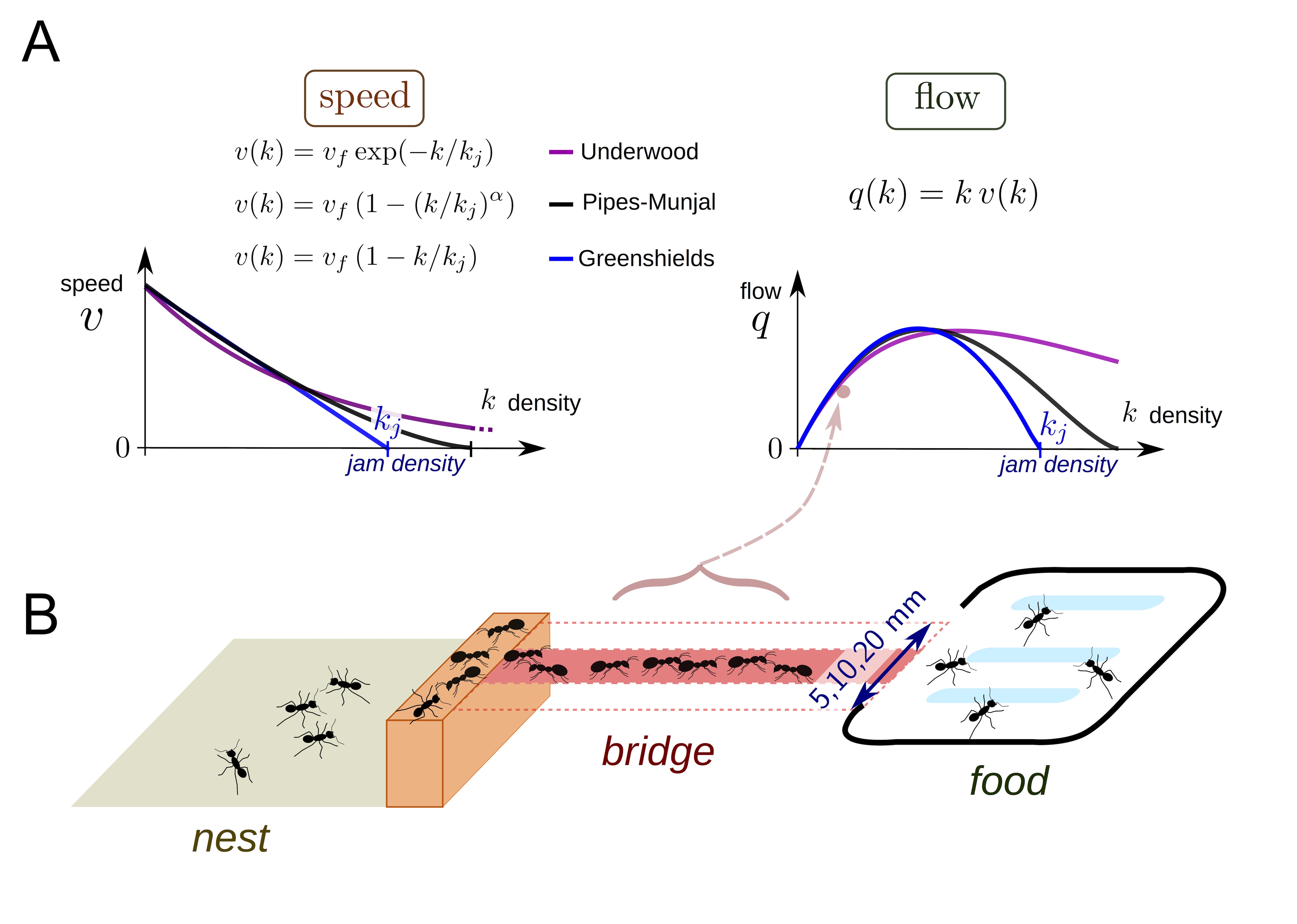
In collective behavior, individual interactors often look out only for their own immediate, short term interest within a crowd. This leads to issues like traffic jams on the road or in crowded pedestrian settings. In general, the flow (speed of moving objects times their density), often increases as density increases until hitting a critical point where the increased density gives rise to a traffic jam and flow begins to decrease. Poissonnier et al. were interested in how ants handle traffic. Unlike human pedestrians or drivers, ants may act more cooperatively in foraging to maximize food acquisition since they share a common goal of raising more young. Today, we will model traffic in ants and see whether they get into jams.
In order to look at ant collective behavior at different densities, the authors starved ant colonies of varying sizes for a few days, and then provided them a foraging object (sugar!) via a bridge of varying width (B). The ants would climb across the bridge to get to the sugar and then return to colony. The variable colony size and bridge width lead to different densities of foraging ants on the bridge, which the authors took (170!) videos of. They measured density and flow across the bridge from the videos. They were interested in how different older models of traffic jams from human behaviors (A) might fit their data and how this might inform whether ants get into traffic while trying to forage.
As this is an eLife paper, the data is (supposed to be) publicly available. There was an issue with the Dryad repository for the data (the DOI link was broken), but the corresponding author very promptly sent me the data when I emailed her. You can download the data set here. We will begin with some exploration for the data before building some models!
[1]:
import numpy as np
import pandas as pd
import bebi103
import bokeh
import bokeh.io
import bokeh.util.hex
import bokeh_catplot
import cmdstanpy
import arviz as az
bokeh.io.output_notebook()
We will read in the data and take a look at the format.
[2]:
df = pd.read_csv("../data/ant_traffic.txt", delimiter="\t")
df.head()
[2]:
| D | F | |
|---|---|---|
| 0 | 0.5 | 0.5 |
| 1 | 0.5 | 0.0 |
| 2 | 0.5 | 0.0 |
| 3 | 0.5 | 0.0 |
| 4 | 0.5 | 0.0 |
Here, 'D' represents ant density (in \(\mathrm{ant}/\mathrm{cm}^2\), based on the figure in the paper), ant 'F' indicates flow, which is \(\mathrm{ant}/\mathrm{cm}/\mathrm{s}\), also based on the figure. The authors generated a lot of data here (170 hour long videos sampled at 1 Hz \(\approx 600,000\) data points), so we might have a little trouble handling that much data with sampling. They use optimization to get their curve fits, which is a reasonable choice since they are
data rich here. To speed things up for the sake of this exercise, I will thin the data stochastically. This shouldn’t influence the modeling much, and I did some testing and found only quite small differences for the samples of the parameters after thinning the data. We will take a look at the thinned data as compared to the full set to do another sanity check that we aren’t losing too much information. With this many data points, transparency doesn’t always capture the distribution of data
points, since it caps out at fully opaque, so I also put a hexplot with a log colormap to get another idea for the data.
[3]:
df_thin = df.sample(n=10000, random_state=24601)
p = bokeh.plotting.figure(
frame_width=250,
frame_height=250,
x_axis_label="Density k (ant/cm^2)",
y_axis_label="Flow q (ant/cm/s)",
title="Thinned Data",
)
p.circle("D", "F", source=df_thin, alpha=0.05)
x, y, hex_size = df_thin["D"], df_thin["F"], 0.5
bins = bokeh.util.hex.hexbin(x, y, hex_size)
q = bokeh.plotting.figure(
match_aspect=True,
background_fill_color="#440154",
frame_width=250,
frame_height=250,
x_axis_label="Density k (ant/cm^2)",
y_axis_label="Flow q (ant/cm/s)",
)
q.grid.visible = False
q.hex_tile(
q="q",
r="r",
size=hex_size,
line_color=None,
source=bins,
fill_color=bokeh.transform.log_cmap("counts", "Viridis256", 0, max(bins.counts)),
)
color_bar = bokeh.models.ColorBar(
color_mapper=bokeh.transform.log_cmap(
"counts", "Viridis256", 0.0001, max(bins.counts)
)["transform"],
ticker=bokeh.models.LogTicker(),
border_line_color=None,
width=30,
location=(0, 0),
label_standoff=12,
)
q.add_layout(color_bar, "right")
s = bokeh.plotting.figure(
frame_width=250,
frame_height=250,
x_axis_label="Density k (ant/cm^2)",
y_axis_label="Flow q (ant/cm/s)",
title="Full Data",
)
s.circle("D", "F", source=df, alpha=0.05)
x, y, hex_size = df["D"], df["F"], 0.5
bins = bokeh.util.hex.hexbin(x, y, hex_size)
r = bokeh.plotting.figure(
match_aspect=True,
background_fill_color="#440154",
frame_width=250,
frame_height=250,
x_axis_label="Density k (ant/cm^2)",
y_axis_label="Flow q (ant/cm/s)",
)
r.grid.visible = False
r.hex_tile(
q="q",
r="r",
size=hex_size,
line_color=None,
source=bins,
fill_color=bokeh.transform.log_cmap("counts", "Viridis256", 0, max(bins.counts)),
)
color_bar = bokeh.models.ColorBar(
color_mapper=bokeh.transform.log_cmap(
"counts", "Viridis256", 0.0001, max(bins.counts)
)["transform"],
ticker=bokeh.models.LogTicker(),
border_line_color=None,
width=30,
location=(0, 0),
label_standoff=12,
)
r.add_layout(color_bar, "right")
bokeh.io.show(bokeh.layouts.gridplot([p, q, s, r], ncols=2))